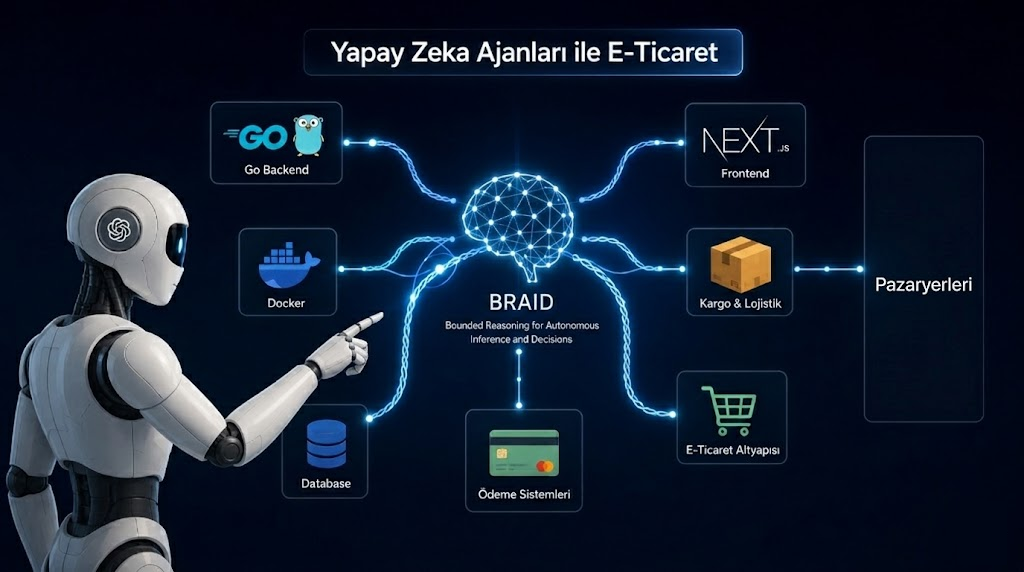
AI Agent’larla Sıfırdan Uçtan Uca E-Ticaret Projesi Geliştirmek: BRAID Mimarisi ve Mermeid Deneyimlerim 💫
Bu yazıda uçtan uca tüm modülleri ile bir e-ticaret projesi yaparken, AI agent’lar ve skill’leri nasıl kullandığımı anlatacağım
Projeyi planlarken ki hedefim, kodları AI agent’larla yönetilebilir kılmak. Sadece “ben de yapay zeka kullanıyorum” demek için değil, gerçekten işime yarayan ve geliştirme sürecini hızlandıran ve kod kalitesini artıran bir sistem kurmak istedim. Bu yazının asıl amacı, kodu üreten ve denetleyen agent’ları tasarlamak
📝 Proje Gereksinimlerini Belirleyelim
Bir projeyi AI agent’larla geliştirmeye başlamadan önce yapılması gereken ilk şey, gereksinimleri mümkün olduğunca net tanımlamak.
Çünkü agent’lar varsayım üreterek çalışırlar. Varsayımlar çoğaldıkça da proje farklı yönlere sapmaya başlar.
Bu nedenle geliştirmeye tek satır kod yazmadan önce kapsamlı bir PRD (Product Requirements Document) hazırladım.
Dokuman çok uzun olduğu için buraya direkt eklemek yerine, linkini paylaşıyorum:
👉 https://github.com/yasinatesim/sklent/blob/master/examples/e-commerce/docs/PRD.md
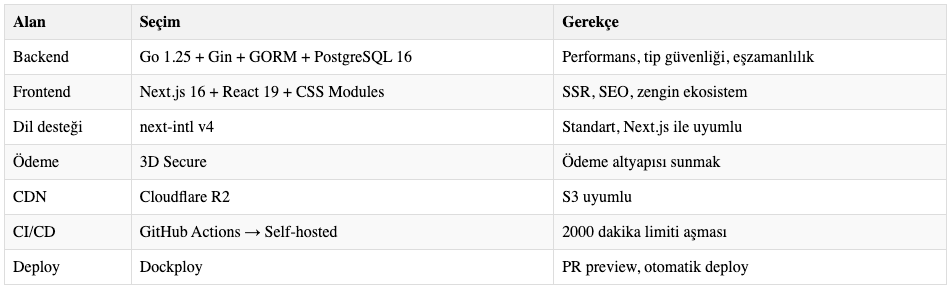
Tech Stack’i inceleyelim:
🧠 AI Agent Ekosistemini Kurgulayalım
Agent’larla çalışırken en sık yaşadığımız sorun şu: model bir adımda hata yapar, sonraki adıma yanlış girdiyle devam eder ve hata büyüyerek ilerler. Buna error compounding deniyor. Düz bir yapılacaklar listesi bunu çözüyor, çünkü listede “başarısız olursa ne olacak” sorusunun yanıtı yok.
Biz bunun için BRAID mental modelini kullandım. Açılımı Bounded Reasoning for Autonomous Inference and Decisions, (kaynak: arXiv 2512.15959) BRAID, karmaşık bir işi dört tür düğüme böler:
Constraint (kısıtlama) → Fact (bilinen gerçek) → Step (eylem) → Check (kontrol)Constraint (bağlamdan çıkan kural), Fact (bilinen gerçek), Step (atomik aksiyon) ve Check (doğrulama). Kritik nokta şu: her Check adımının tam olarak iki çıkışı var, Pass ve Fail.
Basit bir örnekle açıklayayım. Diyelim ki bir ürün kategorisi sayfası yazacağız:
flowchart TD
C1[Constraint: sayfa 1 saniyeden hızlı yüklenmeli]
F1[Fact: 500+ ürün var, pagination lazım]
S1[Step: limit=20 ile SQL sorgusu yaz]
D1[Check: sorgu < 100ms çalışıyor mu?]
S2[Step: index ekle veya query optimize et]
End([End: kategori sayfası hazır])
C1 --> F1 --> S1 --> D1
D1 -- "Pass" --> End
D1 -- "Fail" --> S2 --> S1Eğer bunu grafil oalrak görmek istersek https://mermaid.live/ sitesine yukarıdaki kodu yapıştırarak kontrol edebiliriz, çıktı şu şekilde:
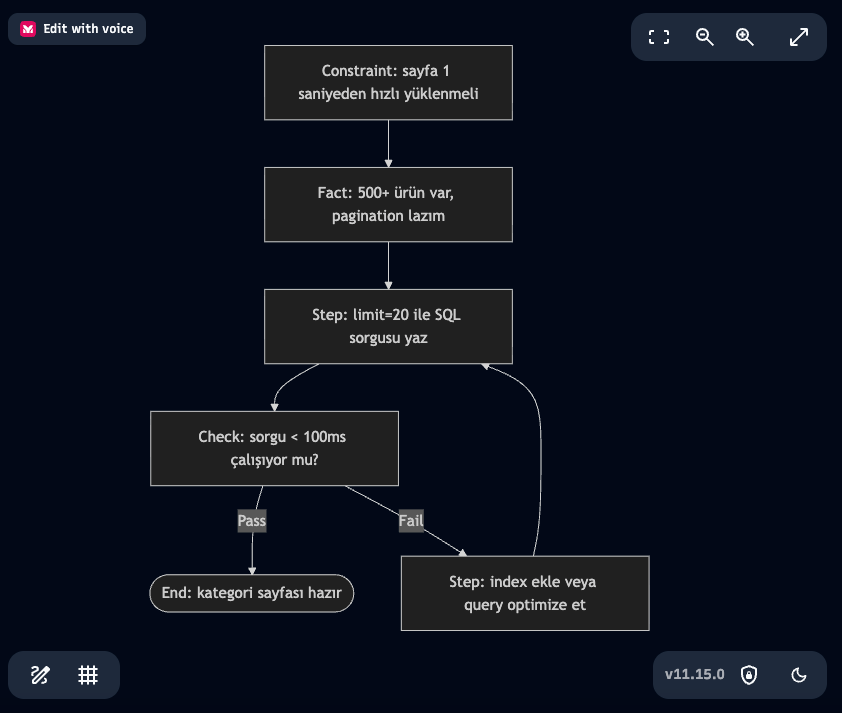
İşin sırrı Fail kenarında. Bir Check başarısız olduğunda model “aynı girdiyle tekrar dene” demez. Bunun yerine daha önceki bir Step’e geri döner, farklı bir girdi üretir ve tekrar kontrol eder. Yani döngünün kendisi retry mekanizmasının ta kendisi olur
💡 Ralph Loop mantığındaki gibi max_retry: 3 gibi sayısal bir sınır koymayız, çünkü BRAID mermeid kullanır ve döngü yapısı zaten bu isteri karşılar
Geliştirmeyle alakalı grafiği bir kez ürettikten sonra proje dizininde .local-artifacts/braid/<task-slug>.mmd altında önbelleğe alırız. Aynı iş tekrar geldiğinde yeniden üretmeyiz, çünkü grafik bir iskelet görevi görür. Bu iki fazlı ayrım (önce mimar üretir, sonra executor adım adım gezer) BRAID'in temel fikri budur. Tek dosyalık bir değişiklik için grafik çizmeyiz tabii. Ama üç dosyadan fazla refactor veya bir mimari karar varsa grafik kullanmamızda fayda var
🤖 Skill Sistemi: Agent’ların Uzmanlaşması
Claude Code’da iki temel yapıtaşı var: agent’lar (kendi context’inde çalışan, belirli araçlara erişimi olan uzman) ve skill’ler (belirli bir görevi anlatan, model çağırınca yüklenen yönerge dosyaları). Bu ikisini bir fabrika hattı gibi kurguladım.
Projenin kök dizininde .claude/ klasörü her şeyin merkezi. İçerisinde proje için tanımladığımız agent’lar, skilller, referance’ler yer alır.
Agent’lara tek bir “her şeyi yap” talimatı vermek yerine, 15 farklı skill (beceri) tanımladım. Her skill belirli bir uzmanlık alanını kapsar:
Skiller

★ Code Review Metrikleri
Bunun için benim en çok kullandığım site skills.sh. Skill’leri ve agent’ları yönlendirirken de genelde “awesome”, “wtf”, “clean code” repository’leri bulup onları kullanıyorum
Örneğin:
- https://github.com/ryanmcdermott/clean-code-javascript — WTFs / min code review metriklerini içeriyor.
- https://github.com/enaqx/awesome-react
- https://github.com/denysdovhan/wtfjs
- https://github.com/benbjohnson/wtf — Go için olan versiyonu

★ Proje planlama için bildiğim skil’ler;
Gerçek kullanıcı gibi test yapan skill veya muadili olan repolar;
- https://github.com/m-taqii/crawlix — Bu repo’yu “playwright-snapshot” SKILL’i haline getirip kullandım. Normalde API üzerinden çalışıyordu
- https://github.com/test-zeus-ai/testzeus-hercules
Her skill kendi SKILL.md dosyası içinde şu bilgileri barındırır:
---
name: braid-plan
description: Generate a BRAID reasoning graph for complex multi-step tasks.
---Skill’lerin içinde adım adım talimatlar, template’ler ve referanslar bulunur. Örneğin wtf-go skill'i Go kodunda hangi pattern'leri arayacağını, hangi hataları bildireceğini ve hangi kuralların ihlal edildiğini tek tek listeler.
Agent’lar ve İş Akışı
Skill’lerin üzerinde 8 farklı agent tanımladım:
- braid-solver — BRAID grafiğini adım adım yürütür
- wtf-code-reviewer — Dispatcher; dosya türüne göre doğru reviewer’a yönlendirir
- wtf-go — Go kodu inceler
- wtf-js-react — TS/TSX kodu inceler
- wtf-security — Güvenlik denetimi yapar
- wtf-ux-playwright — UI testlerini çalıştırır
- constants-guard — Sabit tanımlarında tekrar denetimi yapar
- issue-auditor — Issue’ları yönetir
Bir PR açmadan önceki iş akışımız şöyle:
1. TDD: Önce test yaz, sonra implement et
2. Local doğrulama: go vet, lint, type-check, test
3. wtf-code-reviewer dispatch (tüm reviewer’lar paralel)
4. Eğer UI değişikliği varsa: Playwright snapshot
5. Coverage raporu
6. PR aç (ship-pr skill’i ile)
wtf-code-reviewer agent'ı, bir dosyanın değiştirilip değiştirilmediğine bakar ve buna göre doğru reviewer'ları paralel olarak çalıştırır:
★ api/internal/payment/ değişmiş → wtf-go + wtf-security
★ web/src/**/*.{ts,tsx} değişmiş-> wtf-js-react
★ rendered UI etkileyen her web dosyasi -> wtf-ux-playwright
★ docker/*, *.yml, Dockerfile*, .env* değişmiş -> wtf-security
★ web/src/app/odeme/ değişmiş → wtf-js-react + wtf-ux-playwright + wtf-security
Aggregation kuralı net: herhangi bir uzman reddederse sonuç REJECTED, biri Major bulursa NEEDS_FIXES, hepsi onaylarsa VERIFIED.
Döngü VERIFIED olana kadar sürüyor, en fazla 3 tur. 3 turdan sonra kalan bulgular bize çıkıyor.
Bu yapının güzelliği şu: biz tek bir komut veririz, dispatcher diff’e bakıp doğru uzmanları çağırır ve biz sadece sonucu görürüz. Her uzman kendi context’inde, kendi standart dosyasını okuyarak çalışır, yani biri diğerinin yaptığı şeylerden etkilenmez.
🧩 Hook’lar: Agent’a Sınır Koymak
Bir agent’a kural söylemek yetmiyor, çünkü unutabiliyor veya yorumlayabiliyor. Asıl güç, kuralı mekanik olarak imkansız hale getiren hook’larda. Agent’ların her eylemden sonra ne yapacağını .claude/hooks/ altında tanımladım. Bunlar;
- ★ pre-commit-verify.sh: git commit veya gh pr create sırasında CI'ı birebir aynalayan verify lane'i çalıştırır. Ayrıca master ve development'a doğrudan commit'i ve bilinmeyen branch prefix'lerini bloklar.
- ★ enforce-branch-base.sh: gh pr create sırasında branch prefix ile --base çelişiyorsa bloklar. feature/* mutlaka development'a, hotfix/* mutlaka master'a gitmek zorunda.
- ★ block-pr-merge.sh: gh pr merge'i sert şekilde bloklar. Claude asla PR merge etmez, PR'ı ben merge ederim.
- ★ post-edit-go.sh ve post-edit-ts.sh: her dosya düzenlemesinde lint, format ve named import kontrolü.
- ★ no-long-comments.sh: iki satırdan uzun yorum bloklarını bloklar; çünkü bir WHY iki satırı aşıyorsa kodun yapay zeka tarafından ayzıldığı çok bellidir ve basitleştirilmesi gerekir. (Humanize etmek diyebilriz kısaca 😁)
- ★ constants-guard-trigger.sh: yeni bir UPPER_SNAKE_CASE sabit eklenince constants-guard ‘ı tetikler.
Bu hook’ların felsefesi şu: agent’ın iyimserliğine güvenmek yerine yanlış yapmayı imkansız kılmak. Agent “bu PR’ı merge edeyim” dese bile hook araya girip durdurur. Bu, kuralları “olası” olmaktan çıkarıp “imkansız” yapar.
Proje gereksinimleri veya modeli kullanırken yaşadığımız sorunlara göre hook’ları belirlemeliyiz
CLAUDE.md
Tüm bu sistemin temelinde CLAUDE.md dosyası yatıyor. Bu dosya, projeye başlayan her AI agent'ına "bu projede kurallar bunlar, beklentiler bunlar" diyen bir görevler bütününü içerir:
- Stack ve teknoloji seçimleri
- Non-negotiable kurallar (git-flow, issue zorunluluğu, test politikası)
- Kod standartları ve referance’lar
- Projenin route yapısı
- Pipeline tanımları (bug fix, feature)
En önemli kural: “AI agent never feels time pressure. No shortcuts. Do the full job.” (Yapay zeka ajanı asla zaman baskısı hissetmez. Kısayollara başvurmaz. İşin tamamını yapar.)
Bugünkü modeller, bazen insani duyguları fazla abartıp, “yoruldum”, “bu iş 4 saate biter, uzun süreceği için kısayolu tercih ediyorum” diye çıktılar vererek kestirme yoldan gitmeyi seviyorlar 😅. Onlara sadece basit bir asistan olduklarını hatırlatmak için zaman sınırı olmadığını rahat rahat herşeyi yapmaları gerektiğini hatırlatmakta yarar var 🥲
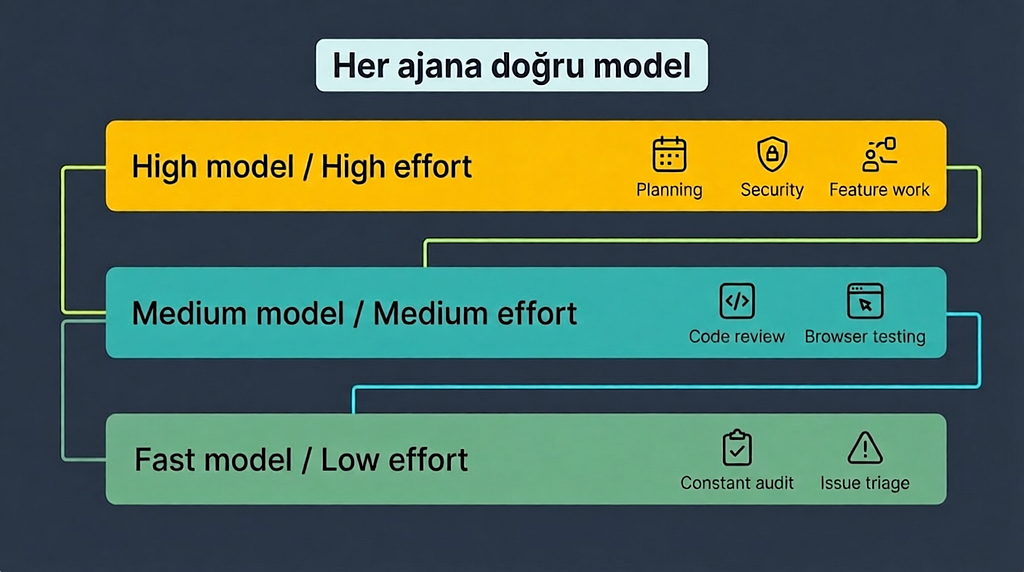
⚙️ Hangi Agent Hangi Modelle ve Ne Kadar Effort ile Çalışır
Burası çoğu yazıda atlanan ama pratikte en çok para ve kalite farkı yaratan kısım. Her agent’a en güçlü modeli vermek hem pahalı hem gereksiz. Biz işi üç sınıfa ayırdık ve her sınıfa farklı bir model ve effort seviyesi atadık.
İlk sınıf, akıl yürütmenin yoğun olduğu işler. Burada bir hata sonradan çok pahalıya patlar, o yüzden en güçlü modeli ve en yüksek effort’u veririz.
★ braid-plan ve spec-driven-development → yüksek model (Opus sınıfı), effort yüksek. Grafiği veya spec’i bir kez üretiyoruz ve sonraki her şey buna dayanıyor; kalitesi her şeyi belirliyor.
★ wtf-security → yüksek model, effort yüksek. Payment bypass, IDOR, mass assignment gibi sınıfları kaçırmak felaket. Güvenlikte false negative en pahalı hatadır.
★ Ana implementasyon agent’ı (yeni, karmaşık feature) → yüksek model, effort yüksek. Sıradan bir refactor’da ise orta modele düşeriz.
İkinci sınıf, kuralı belli olan, daha çok desen eşleştiren işler. Burada orta model ve orta effort yeterli.
★ wtf-code-reviewer (dispatcher) → orta model (Sonnet sınıfı), effort orta. Sadece diff’i okuyup yönlendirme yapıyor.
★ wtf-go ve wtf-js-react → orta model, effort orta. Standart dosyasındaki ret kriterlerine göre eşleştirme yapıyorlar.
★ wtf-ux-playwright → orta model, effort orta. Tarayıcıyı sürüp ekran görüntüsü ve console hatası topluyor; daha çok mekanik.
★ braid-solver → orta model, effort orta. Önbellekteki grafiği gezip adımları uyguluyor; düşünme işini plan fazı zaten yaptı.
Üçüncü sınıf, neredeyse grep’e benzeyen denetimler. Burada hızlı ve ucuz model, düşük effort.
★ constants-guard → hızlı model (Haiku sınıfı), effort düşük. Yeni sabit var mı diye mevcut sabitlerle karşılaştırıyor.
★ issue-auditor → hızlı model, effort düşük-orta. Issue’ları tarayıp duplicate/stale raporu çıkarıyor.
Bunu neden böyle ayırdığımızı açıklayalım: bir reviewer’a Opus vermek, bir grep işine Ferrari koşturmaktır. Tersine, güvenlik denetimini ucuz modele bırakmak ise kapıyı açık unutmaktır. Effort seviyesi de aynı mantıkla: tasarım ve güvenlik yüksek, inceleme ve yürütme orta, denetim düşük.
🧷 Memory: Agent’ların Oturumlar Arası Kalıcı Hafızası
Bir agent her oturuma sıfırdan başlar. Geçen hafta verdiğiniz kararı, çözdüğünüz tuzağı, “şunu bir daha yapma” dediğiniz şeyi hatırlamaz. Bunu çözmek için dosya tabanlı bir memory sistemi kurduk.
.claude/memory/ altında her dosya tek bir gerçeği tutar ve başında bir frontmatter olur. Aşağıda bir memory dosyasının iskeletini görüyorsunuz. Üstünde mantığını, altında alanlarını anlatacağız.
---
name: project-csrf-cookie-domain
description: Prod admin login CSRF_MISMATCH = COOKIE_DOMAIN set edilmemesi
metadata:
type: project
---
Prod'da admin login CSRF_MISMATCH veriyordu çünkü cookie host-only kalıyordu.
Çözüm: COOKIE_DOMAIN=.alanadi.com. İlgili not: [[project-ci-selfhosted]]- name: kısa, kebab-case bir kimlik; başka notlardan [[name]] ile buna link verilir.
- description: recall sırasında bu notun konuyla ilgili olup olmadığına karar veren tek satır.
- metadata.type: dört tür var.
★user (kullanıcı kim),
★feedback (nasıl çalışmam gerektiği),
★project (devam eden iş, koddan çıkmayan kararlar),
★reference (harici kaynak işaretçileri).
Bütün bunların indeksi MEMORY.md dosyasında. Bu dosya her oturum başında context'e yükleniyor; her notun bir satırlık özeti burada. Notların içeriğini buraya koymuyoruz, sadece işaretçi.
Sistemi iki hook ile otomatikleştirdik. SessionStart hook’u oturum açılır açılmaz “önce MEMORY.md'yi oku ve linkleri takip et" diyor. Stop hook'u ise oturum bitmeden "bu konuşmada öğrenilen kalıcı bir şey var mı, varsa kaydet" diye hatırlatıyor.
Bu arada eğer istersek, Claude ve agent ekosisteminde hafıza problemi için geliştirilmiş çeşitli pluginler de bulunuyor. Bunlardan en bilinenleri:
Her iki plugin de agent’ların geçmiş bilgileri vektör veritabanları, embedding tabanlı retrieval mekanizmaları veya otomatik hafıza yönetim katmanları ile hatırlamasını amaçlıyor.
İlk bakışta oldukça güçlü görünseler de pratik kullanımda birkaç problemle karşılaştım:
- Hafızanın neden geri çağrıldığını anlamak zorlaşıyor.
- Embedding ve retrieval katmanları nedeniyle davranışlar bazen tahmin edilemez hale geliyor.
- Yanlış veya alakasız session’lar zaman zaman context’e geri yüklenebiliyor.
- Sistemin nasıl çalıştığını anlamak için ek bağımlılıklar ve karmaşıklık oluşuyor.
Bu yüzden son dönemde daha basit ve yönetilebilir olması açısından .claude/memory klasörü ve iyi tasarlanmış memory notlarının daha verimli olacağını düşündüğümden makalede de bunu paylaştım. Doğrusu bu demiyorum 😃 Ben kendi doğrularımı sizinle paylaştım, herkesin geliştirme stratejisi farklı olabilir.
💰 Token Optimizasyonu
★ Caveman: Agent’ın daha az token kullanması için cevapları sıkıştırıyor. Teknik doğruluğu koruyup gereksiz açıklamaları azaltarak maliyet ve context tüketimini düşürmeyi hedefleyen bir plugin
★ Stop Slop: Yapay zekâ tarafından üretilen metinlerde sık görülen kalıpları, klişeleri ve tekrar eden ifadeleri temizlemeyi amaçlayan bir skill. Daha doğal, daha okunabilir ve daha insan benzeri yazılar üretmeye yardımcı oluyor. README veya dokuman hazırlarken çok işe yarıyor
★ Ponytail: Son dönemde denediğim en ilginç agent skill’lerinden biri. Temel fikri, AI’ın gereğinden fazla kod üretme eğilimini engellemek. “Odadaki en tembel ama en tecrübeli senior geliştirici” gibi davranarak her kod üretiminden önce şu soruları soruyor: Buna gerçekten ihtiyaç var mı? Standart kütüphane zaten çözmüyor mu? Tarayıcı veya platformun yerleşik özelliği yok mu? Mevcut bir bağımlılık kullanılabilir mi? Tek satırla çözülebilir mi? Ancak bunların hiçbiri mümkün değilse yeni kod yazıyor. Sonuç olarak daha az abstraction, daha az bağımlılık, daha küçük PR’lar ve daha okunabilir kod ortaya çıkıyor. Projenin iddiasına göre birçok senaryoda %80–90 daha az kod, daha düşük token maliyeti ve daha hızlı agent çıktıları elde edilebiliyor.
📝 Makalede anlattığım agentic yapı, Ponytail plugini ile çakışabileceği için eğer denemek isterseniz, bu agentic yapıyı kurmadan önce deneyebilirsiniz
Plugin kurmanın kötü yanlarından birisi bu. Eğer çok fazla plugin kurarsak, yeni model çıktığında veya halihazırda bir agentic yapımız varsa, projeyi yönetmeyi zorlaştırıyor. Son dönemde ben olabildiği kadar pluginlerden kaçmaya çalışıyorum 😁
Github zaten artık bence büyük bir plugin cehennemine dönüştü 😁 Yapay zeka modeli üreten şirketler, bizi sürekli bir şeyleri optimize etmeye zorluyorlar 😬
Şimdi projenin detaylarına bakalım, Product Requirements Document (PRD)’ye göre tasarım, Frontend, Backend ve Security geliştirmelerine göz atalım.
🎨 OpenDesign ile UI Tasarımı ve Prototipleme
Kapsamlı bir e-ticaret projesinde sadece backend ve frontend kodu üretmek yeterli değil.
Admin paneli nasıl görünecek?
Ürün kartları nasıl tasarlanacak?
Checkout ekranı nasıl akacak?
Dashboard hangi metrikleri gösterecek?
Normalde bu süreçte Figma açılır, ekranlar çizilir, revizyonlar yapılır ve daha sonra geliştiriciye aktarılır.
Bu projede farklı bir yaklaşım denedim.
UI ve UX tarafında açık kaynak bir tasarım çalışma alanı olan Open Design kullanmaya başladım. Open Design kendisini “Claude Design alternatifi” olarak konumlandırıyor ve agent tabanlı tasarım üretimi üzerine odaklanıyor. Tasarım sistemleri, skill’ler, plugin’ler ve farklı coding agent’larla entegre çalışabiliyor.
Benim kullanım şeklim oldukça basitti:
Yukarıda bahsettiğim PRD’yi Open Design’a verdim ve ilgili ekranları üretmesini istedim
Örneğin:
- Ana sayfa
- Kategori listeleme ekranı
- Ürün detay sayfası
- Sepet ekranı
- Checkout akışı
- Admin Dashboard
- Sipariş yönetim ekranları
- Kampanya yönetimi
- Kupon yönetimi
gibi tüm ekranları PRD üzerinden üretmesini sağladım. Ancak bunu yaparken tek bir index.html de yapmasını istedim herşeyi. Yani sepeet tıklayınca sepet ekranı açılsın, ürün kartına tıklayınca ürün detay açılsın gibi gibi. Bunun sebebi tek index’i Frontend ile ilgilenen Agentlara sağlayıp projenin ona göre oluşmasını sağlamak. Ayrı HTML’lerde parçalı da olabilir tabii ki ama o zaman yönetmek bana daha zor geldiği için tek HTML ile ilerledim tasarım tarafında
🏗️ Backend Mimarisi: Go Paket Düzenini Agent’a Sağlayalım
Go tarafında en çok zorlandığım şey tutarlılıktı. Model bazen named import kullanıyor, bazen tipleri yanlış yere koyuyordu. Bunu çözmek için .claude/references/backend-standards.md içinde kuralları yazdım ve agent'a "her Go işinde önce bunu oku" dedim.
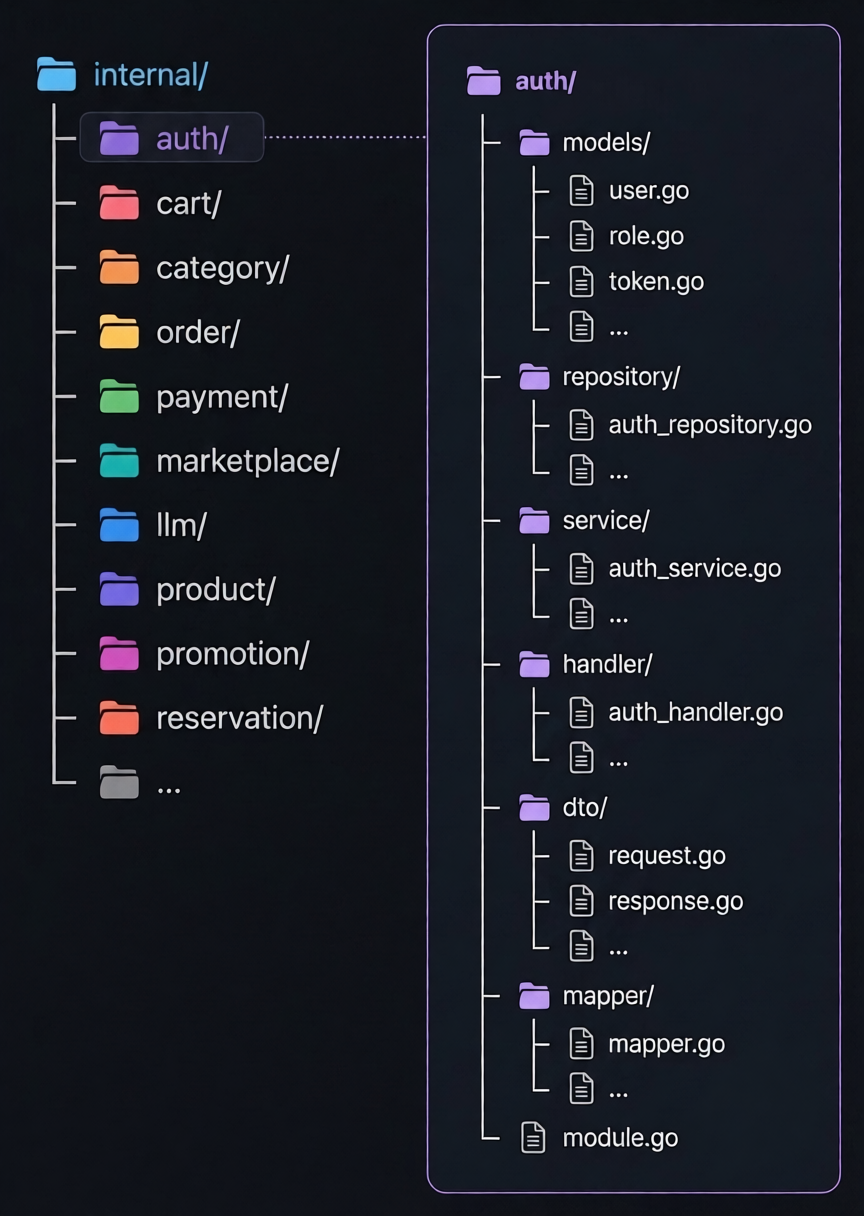
Paket düzeni internal/ altında domain bazlı: auth, cart, category, order, payment, marketplace, llm, product, promotion, reservation ve diğerleri. Tip tanımları her zaman ilgili modülün models/ alt paketinde duruyor.
Test düzeninde Go’nun kendi tree kısıtından doğan iki katmanlı bir kural var.
Black-box (disa acik API) -> <modul>/tests/<isim>_test.go // Ör: product/tests/sorting_test.go
White-box (ic helper'lar) -> <modul>/export_test.go // Ör: product/export_test.go- Black-box testler dışa açık davranışı sorting_test paketinden test eder, gerçek kullanıcı gibi davranır.
- White-box testler export_test.go ile aynı dizinde kalmak zorunda. Taşırsanız build sırasında undefined hatası alırsınız. Go'nun kendi fmt, bufio, bytes paketleri de tam olarak böyle çalışır.
Import kuralı
Agent’ın Go’da named import kullanmasını istemiyorum. alias "pkg/path" yerine çakışma varsa paket bildiriminde yeniden adlandırmayı sağlıyor ama ben bunu istemiyorum. Örneğin üç ayrı modülün models paketi çakışınca, her birinin paket adını package categorymodels, package productmodels diye import edip, alias'sız import ediyoruz. Bunu sadece kuralla bırakmadım, bir hook'la zorunlu kılsım. Her .go düzenlemesinde post-edit-go.sh çalışıp go vet, gofmt -l ve named import kontrolü yapıyor. Başarısız olursa düzenleme bloklanır.
💾 Veritabanı: PostgreSQL 16 ve Migration Stratejisi
golang-migrate/migrate kullandım, migration'lar Go binary içine embed edilmiş.
// embed ile migration dosyaları
//go:embed migrations/*.sql
var migrationsFS embed.FSMigration’lar container ayağa kalkarken otomatik çalışır (docker-compose içinde migrate servisi). Rollback planlı değil, her migration ileri yönlü.
Redis’i rate limiting ve optional cache için kullandım. Redis yoksa in-memory rate limiter devreye giriyor.
🛒 Kullanıcı Akışları: Sepet, Rezervasyon ve Sipariş
Kullanıcı tarafının kalbi sepet ve rezervasyon mekanizması. İki tür kullanıcımız var: misafir (session cookie ile) ve üye. Sepet state’ini frontend’de Zustand ile yönetiyorum, backend ise gerçek stok rezervasyonunu tutuyor.
En kritik kural: kullanıcı ödemeye geçtiğinde stok 15 dakikalığına rezerve edilir. Ödeme başarılı olursa rezervasyon gerçekleşmiş olur, başarısız olur veya süre dolarsa serbest bırakılır. Bu sayede iki kişi aynı son ürünü aynı anda satın alamaz
🏷️ Ürün, Kategori ve LLM ile Ürün Ekleme
Admin tarafının en güçlü özelliği, bir ürünü ham bir başlık ve birkaç görselle ekleyip gerisini LLM’in doldurması. SEO başlığı, HTML açıklama, slug, baskın renk, materyal, anahtar kelimeler ve pazaryeri kategori eşleşmeleri otomatik gelir. Bunu nasıl yaptığımı Kısaca anlatayım:
🧬 RAG ile Sıfıra Yakın Maliyetle İçerik Üretimi
LLM ile içerik üretmenin bir maliyeti var. Bunu düşürmek için daha önce tuvix.js içindeki chatbot projesinde RAG ile bir LLM'e içerik ürettirdiğim deneyimi bu projeye taşıdım. Fikir basit: modele boş bir sayfadan başlatmak yerine, benzer ürünleri bağlam olarak verip daha kısa ve isabetli üretim yaptırmak.
ChromaDB’nin HTTP API’si olduğu için retrieval ve generation’ı doğrudan Go API’nin içinde bir api/internal/rag paketinde yaptım. Benzer ürünleri ChromaDB'den vektörle çekip, OpenRouter üzerinden bir modele (MiniMax sınıfı) başlık ve açıklama ürettirdim. docker compose up dediğimde Postgres, API, web ve ChromaDB birlikte ayağa kalkıyor.
🔗 Marketplace Entegrasyonları
Pazaryeri geliştirmeleri api/nternal/marketplace altında. Her birinde kategori ağacı, attribute'lar, listing ve push akışları var. Kategori verisi sık değişmediği için bir cache katmanı koydum; ilk kullanımda çekip, sonra önbellekten okunur.
intended-vs-implemented skill’i, dokümante edilen davranış ile kodun gerçekte yaptığı arasındaki farkı denetler. Bir agent doğası gereği iyimserdir, "evet bu çalışır" demeye meyillidir. Biz hem reference'lara hem de bu skill'e "varlık tamlık değildir, iddia etmeden önce koda bak" prensibini koyarak bu iyimserliği frenledik.
💳 Ödeme Entegrasyonu
Ödeme tarafı en hassas yer, çünkü burada hem para hem stok var. Iyzico 3D Secure akışını api/nternal/payment altında kurguladım. Kullanıcı 3DS doğrulamasını tamamlayınca, bize bir callback gönderiyor.
Callback handler’ının mantığı şu sırayla ilerler. Önce zorunlu alanlar var mı, sonra 3DS doğrulaması başarılı mı, sonra sipariş gerçekten var mı, sonra ödenen tutar sipariş tutarıyla birebir tutuyor mu. Her adımda bir hata varsa rezervasyonu serbest bırakıp kullanıcıyı hata sayfasına yönlendiririz
Bu akışı yazarken wtf-security reviewer'ı sürekli devredeydi. En çok yakaladığımız bulgu "payment bypass" olduğu için. Callback'i doğrulamadan siparişi ödendi işaretlemek gibi. Reviewer bu deseni görür görmez CRITICAL olarak işaretler ve PR'ı bloklar. Sandbox tarafında test ortamı ile çalıştım; gerçek kart bilgisi olmadan tüm 3DS akışını uçtan uca denemiş oldum
📦 Kargo ve Sipariş Takibi
Kargo tarafını sade tuttuk: sabit ücret (flat rate) ve admin panelinden manuel takip numarası girişi. Admin bir siparişi kargoladığında takip numarasını girer, sistem siparişi “kargolandı” durumuna alır ve müşteriye e-posta gider.
📧 Email Sistemi: React Email + Stalwart
Email template’leri için React Email kullandım. Component bazlı email tasarımı, hot-reload destekli bir render server ile çalışıyor.
SMTP olarak self-hosted Stalwart mail server kullandım. Template’ler container içinde render edilir ve Stalwart üzerinden gönderilir.
Emailler:
- Sipariş onayı
- Şifre sıfırlama
- Email doğrulama
- Düşük stok uyarısı (admin’e)
- İade durum güncellemesi
🧾 Fatura: GIB e-Arşiv Entegrasyonu
Fatura tarafı için GIB e-Arşiv portalına bağlanan ayrı bir entegrasyon var. Burada ilginç bir teknik problem çıkıyor: e-Arşiv portalı CORS izni vermiyor, yani tarayıcıdan doğrudan istek atamıyorsunuz. Çözüm olarak istekleri kendi sunucumuzdaki bir proxy üzerinden geçiriyoruz.
👑 Admin Paneli: Tam Yetkili Yönetim
Admin paneli, frontend’de /admin rotası altında, backend'de api/internal/admin/ paketinde yer alıyor
Dashboard: Günlük siparişler, gelir, ziyaretçi istatistikleri
Ürün Yönetimi: CRUD, bulk update, AI enhancement, image manager
Kategori Yönetimi: Site için kullanılan ve marketplace’lerin kendi platformlarındaki kategoriler.
Sipariş Yönetimi: Listeleme, filtreleme, kargo takibi, ödeme onayı
Promosyonlar: Yüzde/para indirimi, sepet/ürün/kategori kapsamı
Kuponlar: CRUD + misafir kullanıcılara atama
Müşteriler: Listeleme, sipariş geçmişi
İncelemeler: Onay/red moderasyonu
İadeler: Durum yönetimi
İçerik: Banner ve home rail yönetimi
Analytics: Event bazlı istatistikler
Denetim Günlüğü: Tüm admin aksiyonları loglanır
Admin’e erişim sadece admin rolüne sahip kullanıcılara açık. Tüm admin isteklerinde CSRF koruması var.
🌐 Frontend: Next.js 16
Frontend’de Next.js 16 ve React 19 kullandım. CSS Modules + SCSS ile stil yönetimimizi yapıyoruz. Tailwind kullanmadım. Kendi Design sistemim üzerinden ilerlemek istedim
i18n: Çoklu Dil Desteği
next-intl v4 ile iki dil desteği mevcut. Dil dosyaları JSON formatında ve feature-based organize edilmiş:
web/src/shared/i18n/messages/
├── tr.json # Türkçe
└── en.json # EnglishHer dil dosyası şu şekilde yapılandırılmış:
{
"home": { "hero": { "title": "...", "subtitle": "..." } },
"product": { "addToCart": "...", "stock": "...", "reviews": "..." },
"admin": { "products": { "list": "...", "create": "..." } },
"checkout": { "payment": "...", "shipping": "..." }
}Middleware’de dil tespiti yapılıyor ve yönlendirme otomatik olarak gerçekleşiyor
State Yönetimi: Zustand
React Context API yerine Zustand kullanıyoruz. Sepet, modal, toast bildirimleri ve çerez onayı Zustand store’ları ile yönetiliyor.
Frontend kodumuzda sıkı kurallarımız var:
- Her dosyada tek component
- Arrow function + default export
- Status-based state management (isLoading/isError boolean) — Loading, Error ve Empty State Nasıl Daha İyi Yönetilir? ✨ makalemde anlatmıştım.
- Dispatch object map (JSX’te ternary tree yok)
- Inline style yasak, sadece CSS Modules
- SVG icon’lar merkezi components/icons/ altında
Admin paneli ayrı bir modüler yapıda. 12 alt modülü var: products, orders, promotions, coupons, categories, customers, analytics, banners, home-rails, reviews, returns, dashboard. Her modül kendi view’ları, store’u ve component’leri ile bağımsız
🛡️ Güvenlik: İki Katmanlı Yaklaşım
Güvenliği iki ayrı katmana böldüm:
Birincisi sürekli katman:
wtf-securityskill’i dispatcher tarafından auth, payment, middleware, input handler, docker compose veya env şablonlarına dokunduğunda otomatik tetiklenir. Saniyeler içinde çalışır ve her PR'da çalışır.
İkincisi periyodik katman: security-pentest. Bu, dinamik bir pentest ve üç alt skill'i var:
- web app pentest (Next.js akışları),
- API pentest (JWT, IDOR, rate limiting, iş mantığı)
- Network pentest (TLS, header'lar, açık portlar, DNS).
Bunları büyük sürümler öncesi ve üç ayda bir paralel çalıştırırız.
Auth tarafında JWT 15 dakikalık access ve 7 günlük dönen (rotating) refresh token, httpOnly cookie, CSRF double-submit koruması ve rate limit var. Rate limit kurallarını rota bazında tanımladım.
Bu skill’i geliştirirken, yine skills.sh’da bulduğum security skillerinden ve şu repo’dan faydalandım:
Ancak güvenliği yalnızca AI agent’ların yaptığı incelemelere bırakmak istemedim.Bu nedenle GitHub Actions tarafında da ikinci bir güvenlik hattı kurdum.Her Pull Request açıldığında aşağıdaki güvenlik kontrolleri otomatik çalışıyor:
Secrets Scan (Gitleaks)
İlk kontrol katmanı Gitleaks.
Amaç; yanlışlıkla commit edilmiş API key, JWT secret, access token, SMTP şifresi veya diğer hassas bilgilerin repoya girmesini engellemek.
Agent veya geliştirici fark etmeksizin bir secret repoya sızmaya çalışırsa pipeline başarısız oluyor.
SAST — Go (Semgrep)
Backend tarafında Semgrep ile statik analiz çalıştırıyorum.
Bu aşamada:
- SQL Injection
- Command Injection
- Hardcoded Secret
- SSRF
- Path Traversal
- Güvensiz Kriptografi Kullanımı
gibi yaygın güvenlik problemleri taranıyor.
SAST — TypeScript (Semgrep)
Frontend tarafında da ayrı bir Semgrep pipeline’ı bulunuyor.
Burada özellikle:
- XSS riskleri
- Güvensiz HTML render işlemleri
- LocalStorage üzerinde hassas veri kullanımı
- Güvensiz fetch çağrıları
- Authorization akışındaki problemler
tespit edilmeye çalışılıyor.
🐳 Docker ve CI/CD: Production’a Giden Yol
Üç katmanlı Docker compose yapımız var:
Base (docker-compose.yml): postgres, migrate, api, web, redis
Dev (docker-compose.dev.yml): + mailhog (local mail için), + email-renderer, + seed data
Prod (docker-compose.prod.yml): + stalwart SMTP (prod mail için)
🧨 Dockploy ile Preview Deploy
Her PR şu şekilde otomatik preview deployment çalışır:
http://preview-siteadi-web-pwrqoq-heiknc.siteadi.com/
Bu sayede değişiklikleri production'a almadan önce gerçek ortamda görebiliyoruz.
E2E testleri preview URL hazır olduğunda çalışıyor. Playwright snapshot’ları alınıyor ve PR comment’i olarak ekleniyor.
☁️ CDN: Cloudflare R2
Ürün görselleri Cloudflare R2'de saklanıyor. R2'yi tercih etme nedenim: S3 uyumlu API, egress ücreti yok, Cloudflare paneli üzerinden hızlı erişim.
⚙️ CI/CD: 2000 Dakika Limiti ve Self-Hosted Runner’a Geçiş
Tam “her şey yolunda action’lar güzel güzel çalışıyor” derken, Github’dan şöyle bir mail geldi 😅
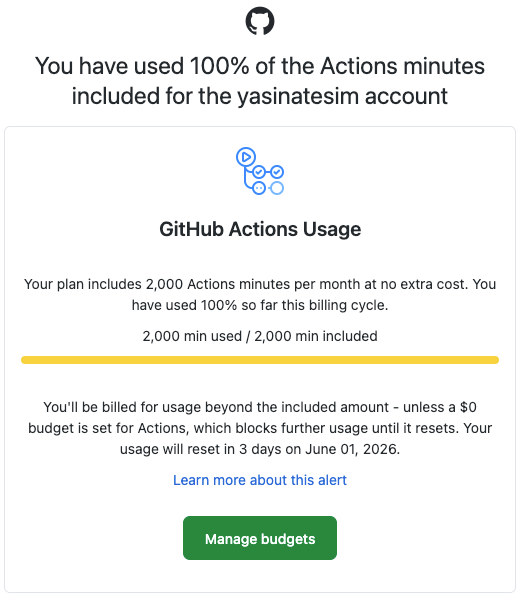
Her PR’da lint, type-check, test, coverage ve UI tarafında Playwright çalışır. Backend ve frontend ayrı job’lar. Bu Github Action, dakikalarını hızla yiyor, özellikle benim gibi Playwright da geliştirme yaparken, belirli Best Practice’lere uymayı unuttuysanız.
Playwright Best Practice’leri ile alakalı Kader’in güzel bir yazısı vardı. Geçenlerde denk gelmiştim, linkini bırakayım:
👉 https://medium.com/@kaderkaaya/building-a-playwright-based-crawler-test-system-without-overloading-production-035207504ff6
Bu Best Practice’leri uyguladıktan sonra çözüm self-hosted runner’a geçmek oldu. Kendi makinemde bir runner ayağa kaldırdım ve workflow’ları runs-on: self-hosted olarak işaretledim. Aşağıda CI dosyasından bir kesit var.
jobs:
filter:
name: Detect changed paths
runs-on: self-hosted
timeout-minutes: 5
steps:
- uses: actions/checkout@34e114876b0b11c390a56381ad16ebd13914f8d5 # v4
- uses: dorny/paths-filter@d1c1ffe0248fe513906c8e24db8ea791d46f8590 # v3
id: changes
with:
filters: |
backend:
- 'examples/e-commerce/api/**'
frontend:
- 'examples/e-commerce/web/**'Self-hosted runner’ın bir bedeli var tabii: runner’ı temiz tutmak. Her iş bittiğinde container’lar, dangling image’lar ve cache birikir. Bunun için ayrı bir runner-cleanup.yml workflow'u yazdım; periyodik olarak makineyi temizler. Self-hosted'a geçerken bu temizlik adımını atlamayın, yoksa diskiniz birkaç gün içinde doluyor.
🚀 Tüm Bunları Açık Kaynak Yaptım: Sklent
Bu süreçte öğrendiğim her şeyi açık kaynak bir repoya taşıdım.
Repo 👇
https://github.com/yasinatesim/sklent
Ama repoyu sadece bir e-ticaret demosu olarak değil, asıl mesele olan agent ekosistemi öne çıkacak şekilde kurguladık. Repo aslında teknik olarak bir agent bootstrap: herhangi bir projeye eklenebilen, agent + skill + reference + hook setinden oluşan, BRAID etrafında kurulu bir iskelet. Adını Sklent koydum.
Proje dizininde en baştaki README de bir gist linki paylaştım.
👉 https://gist.github.com/yasinatesim/bd5230ca0cc9b033c16280813c3ce6ff
Bu Gist benim bu tüm süreci tasarlarken oluşturduğum Agent ve SKILL yapısını tek prompt ile oluşturmayı sağlıyor.
E-ticaret uygulaması ise examples/e-commerce/ altında, markasız "Vela Commerce" olarak yaşıyor. Yani okuyan kişi repoyu açar açmaz amacın "bir e-ticaret scripti satmak" değil, "agent ekosistemini göstermek" olduğunu anlıyor.
📬 Geri Bildirim
Makaleyi yazarken, kaynakları belirleme ve araştırma için kendi notlarımı, yazım denetimi ve ek araştırma için Claude Fable 5 (kapanmadan önce 🥲) ve GPT-5.2 High modellerini kullandım. Resimleri üretmek için ise Gemini 3 Pro Preview 2k (Nano Banana Pro) modelini kullandım.
Yazı ile ilgili tavsiye, öneri, eleştirileri dikkate alıyorum. İletişime geçmek isterseniz bana websitemdeki sosyal medya adreslerimden veya Linkedin üzerinden ulaşabilirsiniz.
Sevgiyle kalın, Yasin 🤗
📚 Makaleyi Yazarken Kullandığım Kaynaklar
- BRAID: Bounded Reasoning for Autonomous Inference and Decisions (arXiv 2512.15959) — Agent akıl yürütmesini grafikle yapılandırma mantığı için temel kaynak.
- Claude Code — Subagents — Uzman agent’ları tanımlama ve paralel çalıştırma.
- Claude Code — Agent Skills — Skill yapısı ve description tabanlı tetikleme.
- Claude Code — Hooks — Olay tabanlı hook’larla kuralları zorunlu kılma.
- Anthropic Cookbook — Gerçek dünya agent örnekleri.
- mukul975/Anthropic-Cybersecurity-Skills — Güvenlik skill’lerinin yapılandırılması için ilham.
- https://github.com/rohitg00/agentmemory — Claude’a agent bazlı memory eklemek için
- https://github.com/thedotmack/claude-mem — Claude’a memory eklemek için
- https://github.com/juliusbrussee/caveman — Caveman stili ile token optimizasyonu
- https://github.com/hardikpandya/stop-slop — Klişe ifadeleri ve tekrar eden ifadeleri temizlemeyi sağlayan skill
- https://github.com/DietrichGebert/ponytail — AI’ın gereğinden fazla kod üretme eğilimini engelleyen tembel SR dev skill’i
- phuryn/pm-skills — intended-vs-implemented skill'i için ilham (MIT).
- Go Dokümantasyonu — Backend dili ve paket düzeni kuralları.
- Gin Web Framework — HTTP router ve middleware.
- GORM — ORM ve mass assignment güvenliği.
- PostgreSQL 16 — Veritabanı ve kilitleme.
- Next.js — Frontend framework.
- next-intl — JSON tabanlı i18n yönetimi.
- Zustand — Sepet ve UI state yönetimi.
- ChromaDB — RAG için vektör retrieval.
- OpenRouter — LLM sağlayıcı erişimi.
- GitHub Actions — Self-Hosted Runners — Dakika limitini aşma çözümü.
- GitHub Actions — Faturalandırma — 2000 dakika limitinin kaynağı.
- Dockploy — Push’ta otomatik pull ve preview ortamları.
- Cloudflare R2 — Statik içerik ve görseller için CDN.
- yasinatesim/tuvix.js (chatbot) — RAG ile içerik üretimi için taşıdığım önceki deneyim.
- Tek Prompt İle Kendi AI Agent Ekosistemini Kur (Yasin Ateş — Medium) — Agent-bootstrap fikrini ilk paylaştığım yazı.
- agent-bootstrap gist (Yasin Ateş) — Tek prompt ile agent/skill altyapısını kuran bootstrap dokümanı.
- Building a Playwright-Based Crawler Test System Without Overloading Production (Kader Kaya — Medium)
- https://claude.com/plugins/ralph-loop — Claude’un Ralph Loop eklentisi
- https://github.com/nexu-io/open-design — Claude Design’ın Open Source alternatifi
- Loading, Error ve Empty State Nasıl Daha İyi Yönetilir?